
微軟發表AI模型Kosmos-1 看得懂圖片及影像
記者/竹二
微軟近日公布一項AI模型Kosmos-1,不僅可以理解文字,還能看懂圖片及影像,可用於處理更多任務,像是為影片加字幕說明、看圖片回答問題、正確搜尋網頁資訊等。
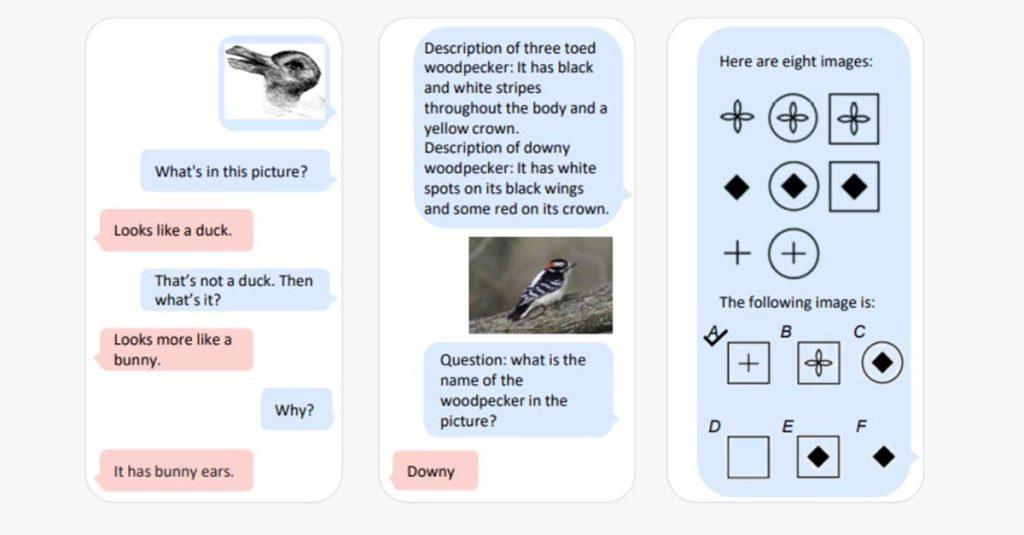
微軟日前在一篇名論文中指出,雖然現行大型語言模型在自然語言處理有很成功的應用,但對於文字、聲音及圖像資料,仍然很難原生使用大型語言模型,若能增加這類的能力,將能大幅拓展語言模型用於高價值任務的可能性。因此,微軟提出多模大型語言模型(Multimodal Large Language Model,MLLM)Kosmos-1,希望具備常見多模態(如圖像、文字、聲音)資料、依循指令並在特定條件中學習的能力。
據了解,微軟以多種任務來評估訓練完成Kosmos-1模型,包含語言理解、常識理解、非口語推理、為圖片加文字說明或回答視覺相關的提問,以及零樣本視覺資料的分類及描述等。實驗結果顯示,小型Kosmos-1模型在零樣本的圖像加文字說明的任務表現優異,在回答視覺問題方面,只要少量樣本訓練過,Kosmos-1表現可優於其他模型。
而在常用的IQ測驗中,Kosmos-1也展現出能理解題目中圖片資料的概念規則,還能自行推論、預測接下來出現的圖片。相關研究人員表示,這是第一個能作答零樣本Raven IQ test的模型,雖然該模型和普通成人的推論能力還差一截,但展現出零樣本語言模型的非口語理解能力具有相當潛力。
據悉,微軟未來計畫將Kosmos-1再擴大,並整合語言能力,微軟相信多模態大型語言模型處理多型態資料的能力,可以整合介面提供多模學習,協助使用指令和範例來控制以語言生成圖像的AI 工具。
瀏覽 1,046 次





