AI攻擊普及化?— 論攻擊模式與原因|專家論點【Howie Su】
作者:Howie Su(產業分析師)
人工智慧危害事件已經越來越頻繁
如果人工智慧模型本質上是安全的,那麼NIST、FDA、ISO、ETSI、ENISA等知名組織以及歐盟人工智慧法案等監管工作不會使「安全可靠的人工智慧」成為值得信賴的人工智慧的基本要素。讓我們把時間轉回 2017 年,一串人工智慧的意外不知道大家還有沒有印象:一個名為Promobot IR77的人形機器人試圖逃跑、NASA 的 CIMON 表現出了意想不到的行為、特斯拉的自動駕駛汽車成為人工智慧操縱的犧牲品。而在最近的事件中,美國國家飲食失調協會 ( NEDA ) 被迫關閉其聊天機器人Tessa,因為該機器人向尋求飲食失調問題建議的使用者提供有害建議;同時,微軟Tay AI模型原先為模仿千禧世代的語音模式,但它卻失控了,做出了諸如「布希就是911攻擊點元兇」的虛假言論。這些事件凸顯了人工智慧對人身安全、經濟、隱私、數位身分甚至國家安全的潛在威脅,人工智慧系統還可能導致智慧汽車忽視停車標誌,誘使醫療系統批准有害流程,誤導無人機執行任務,並繞過內容過濾器在社交平台上傳播謠言等,這些問題已經神不知鬼不覺地滲透我們的生活,而多數人依舊一無所知。
所以,什麼是人工智慧攻擊?
從廣義上講,機器學習模型可以透過三種不同的方式受到攻擊,例如
- 被愚弄做出錯誤的預測,例如,將停車標誌分類為綠燈
- 透過數據進行更改,例如使其有偏見、不準確甚至惡意
- 複製或竊取,例如,透過持續查詢模型來竊取 IP
對抗性人工智慧攻擊有多種形式,每種形式都有獨特的意圖和影響,第一種攻擊是「逃避攻擊」,攻擊者巧妙地操縱人工智慧系統來產生錯誤的結果。想像一下,由於一小段膠帶,自動駕駛汽車中的人工智慧誤讀了停車標誌,如此小的操縱可能會產生重大後果,其他攻擊則針對安全的核心原則:機密性、可用性和完整性;第二種稱為「資料危害」,攻擊者導入有害資料來破壞人工智慧的學習過程,他們甚至可以安裝隱藏的暗門,等待合適的時機造成嚴重破壞;第三種則是「提取攻擊」是一種對 AI/ML 模型進行逆向工程並存取其訓練資料的方法,正如NSA 的所描述的:「如果使用敏感資料來訓練人工智慧,攻擊者可能會查詢使用者的模型以洩露其設計或訓練資料」。
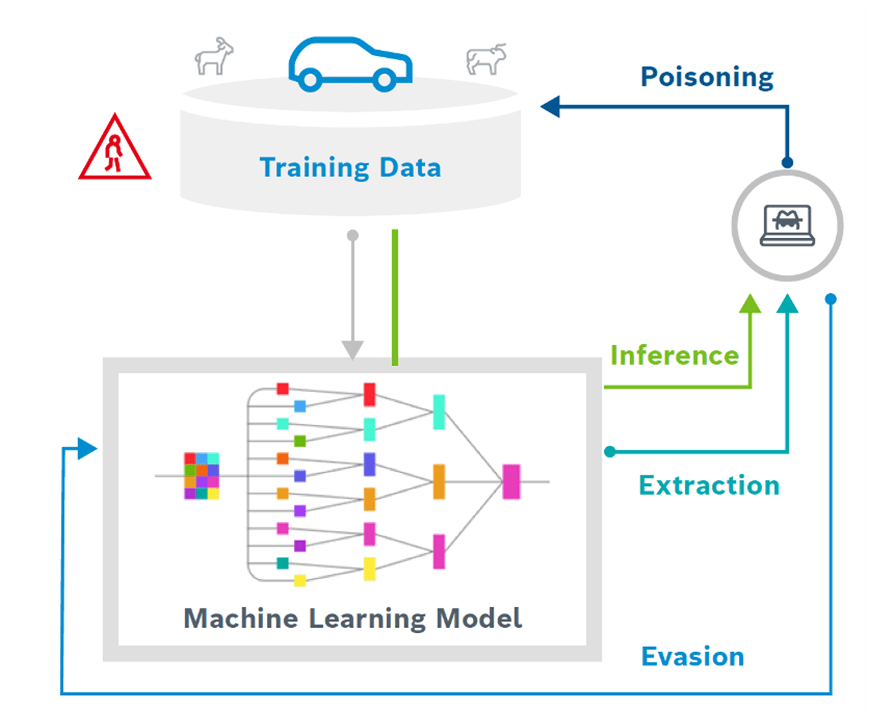
是什麼讓人工智慧更容易受到攻擊?
由於現代機器學習方法的固有特徵,使得人工智慧系統很容易受到攻擊,該技術主要存在三個主要漏洞,在「善加利」用後容易造成更大危害,這些都是企業在導入技術時需要更加提防的潛在弱點。
- 機器學習模型如何學習:人工智慧透過脆弱的統計相關性進行學習,這種統計相關性雖然有效,但很容易被破壞。攻擊者可以利用這種脆弱性來創造和發動攻擊。
- 完全依賴數據:機器學習模型完全由數據驅動。如果沒有基礎知識,他們很容易受到數據中毒的影響,惡意數據會擾亂他們的學習。
- 演算法不透明:尖端演算法像黑盒子一樣運行,尤其是深度神經網路。由於缺乏透明度,很難區分真正的效能問題和外部攻擊。
瀏覽 767 次