
人工智慧內容生成如何重塑產業樣貌|專家論點【Howie Su】

深度學習強化內容生成質與量
自2014年開始,生成式對抗網路帶動深度學習演算法快速發展,由電腦生成內容擺脫過去笨拙、無情感、低邏輯的狀態,更多的資料帶來更多想像力,也吸引科技業者投入,例如微軟的「小冰」、DeepMind的DVD-GAN、NVIDIA的Style GAN、Open AI的DALL-E-2,這些模型已經開始朝向高品質應因內容製作,甚至繪出抽象藝術風格的作品,人工智慧內容生成(AI Generated Content,AIGC)在深度學習演算法快速發展、企業與社會在數位經濟發酵下產生大量數據、人機協作正夯的三大要素驅動下,已經開始改變整個產業與社會樣貌,除了「編輯」功能外,也開始朝向「創作」邁進,加上元宇宙的風潮持續,未來的作品將難以分辨是由人或是電腦製作,或是兩者合力完成,同時搭配AR/VR整合虛實經濟。
人工智慧大模型架構帶來技術快速升級
參數是機器學習演算法的關鍵要素,猶如馬斯克與貝佐斯的太空競賽,科技巨頭的軍備競賽是「誰有最大深度學習的模型」,而參數的數量在這兩年成長速度相當驚人:2018年最大的模型有9,400萬個參數,2021年最大的模型1.6兆個參數,最大主因為Google、Meta、Microsoft、Amazon等巨頭推波助瀾所致,一方面向業界展現驚人的人工智慧競爭力,一方面也探索參數數量的極限,雖然許多聲音指出,越大的模型並不一定適合用在每個場域,但有能力開發出超參數模型(Hyper-parameterized models)的業者也代表不斷推進演算法的疆界。
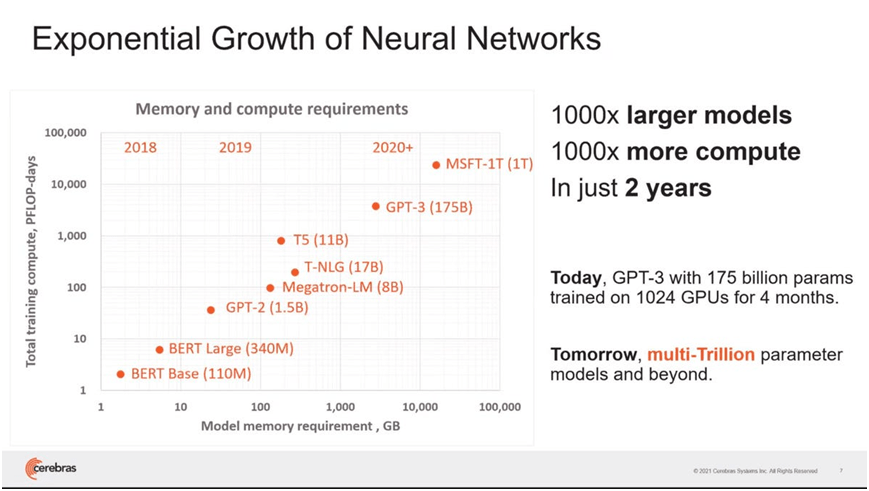
這些超參數模型多為語言模型(Language-based model),讓電腦可以撰寫報告、翻譯、文案、程式、遊戲等,甚至還能辨認語意中是否帶有諷刺或威脅性質的詞語。較著名的例子為GPT-3,一個由在舊金山的非營利人工智慧組織OpenAI訓練與開發出來的大型模型,包含1750億個參數,這個模型目前由微軟於2020年取得獨家授權,自然也被列進模型戰爭的軍火庫。事實上,微軟也是OpenAI的股東之一。未來大型模型可能有科技公司或是一個/多個團隊開發,但可以確定的是,目前探索參數在模型中的極限是人工智慧發展的重要里程碑。
能夠大規模預訓練的語言模型除了在語意分析、語音識別、資訊辨識等文本理解場景中發揮作用外,在廣告製作、內容生成的潛力也不可小覷,透過給予大量文字與圖像,讓模型尋找彼此的關聯性,再透過重複學習,模型能隨著給定圖像的不同而有不同判斷,例如OpenAI的模型能在給定一圖像後根據圖像中的內容物下標,例如「一隻柯基坐在椅子上」,經過不斷重複訓練,人工智慧將從理解內容與定義內容,逐步走向創作內容,從畫法、藝術風格、通過圖靈測試,都不再是遙不可及的夢想,甚至進行量產、拍賣,帶來可觀收益。
媒體業的人機協作時代來臨?
當然,受影響最大之一的產業為媒體業,採訪助理、文稿自動生成、影音與字幕生成改變媒體的內容生產模式,內容可以搭配什麼樣的圖、用什麼樣的口吻撰寫都可以調整。美聯社就以Wordsmith智慧稿件生成平台撰寫2,000篇報導,北京在2022年冬奧會議上也使用人工智慧內容剪輯,部分媒體業也開始用虛擬主持人/智慧主播分身的方式報導新聞,部分語音設備在採訪同時能自動生成新聞稿,媒體業身為最古老行業之一,正面臨深層變革。
瀏覽 2,989 次





