
DeepMind發表Genie 用圖片即可生成AI遊戲世界
記者/竹二
繼OpenAI發表Sora模型之後,近日Google DeepMind也推出一個令人不可思議的Genie,這是一個靠網路影片訓練出來的AI生成模型,可以藉由文字、圖片、照片甚至是草稿,生成無數種可以遊玩、角色動作可控的2D虛擬世界。
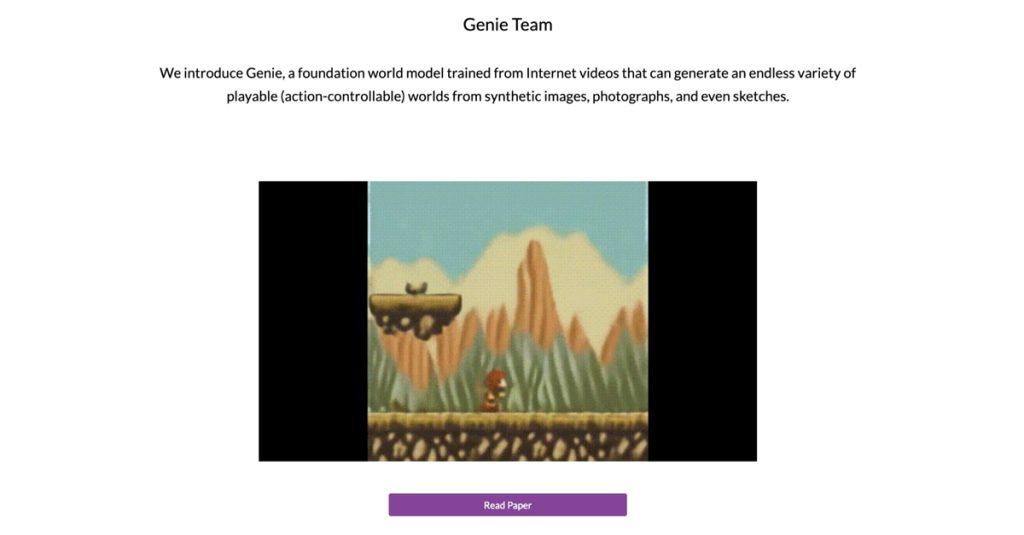
Genie全名為Generative Interactive Environments,是利用公開且長達20萬小時的線上網路影片訓練而成,與Sora不同的地方在於,Genie可以創建出可操控的世界,而不單單只是影片,單靠文字、圖片、影片甚至是手繪草圖就可以生成出真正可以遊玩、可以互動的虛擬遊戲世界。
更多新聞:Google DeepMind「機器人憲法」 推動負責任的機器人研究
值得一提的是,Genie是在沒有人監督的情況下,使用未進行動作標記的影片來進行訓練,但卻能學習網路影片中的各種角色在運動、控制與動作時的樣子,可以對於現實世界的物理狀態有更深入的理解,未來有可能有助於實體機器人更好理解並與身邊環境互動。
Genie是朝向AGI通用世界模型的一步
Google DeepMind開發者Tim Rocktäschel在X上po文提到,Genie不僅僅局限於 2D,他們針對機器人數據(RT-1)進行訓練,在不預設任何動作的情況下,證明同樣能創建出一個可控制動作的模擬系統,他們認為這是朝向AGI通用世界模型有希望的一步。
據悉,Google並不是第一次透過網路影片來訓練AI模型,今年稍早DeepMind Robotics的團隊就發表了一款名為AutoRT的AI模型,可結合大型基礎模型(像是LLM)或是視覺語言模型(VLM)與機器人控制模型(RT-1或RT-2),來達到不同的任務目的。
瀏覽 700 次





