
Meta釋出新模型V-JEPA 發展AI高階機器智慧
記者/竹二
Meta近日釋出基於由首席人工智慧科學家Yann LeCun提出的人工智慧模型架構JEPA,所架構的新模型V-JEPA,公開用於預測影片中缺失部分,透過預測影片中缺失或是被遮蔽的部分,建立人工智慧對真實世界的理解,可作為發展高階機器智慧的基礎。
JEPA架構可建立AI智慧
據了解,Yann LeCun是在2022年時提出JEPA架構,目標是建立進階的機器智慧,讓AI可以像人類一樣學習,建立起周圍世界的內在模型,以便學習及適應,有效制定計畫,完成複雜的任務,而所謂的內在模型,指的是人類或AI在大腦或神經網路中所建構的心智,反映出對於世界的理解。
Meta在2023年時就運用JEPA架構開發電腦視覺模型I-JEPA,特色在於可以關注真正的圖像重點,能夠以更像人類理解抽象表示的方法,來預測缺失的資訊,現在Meta進一步擴展JEPA架構,發展可以處理影片的V-JEPA。
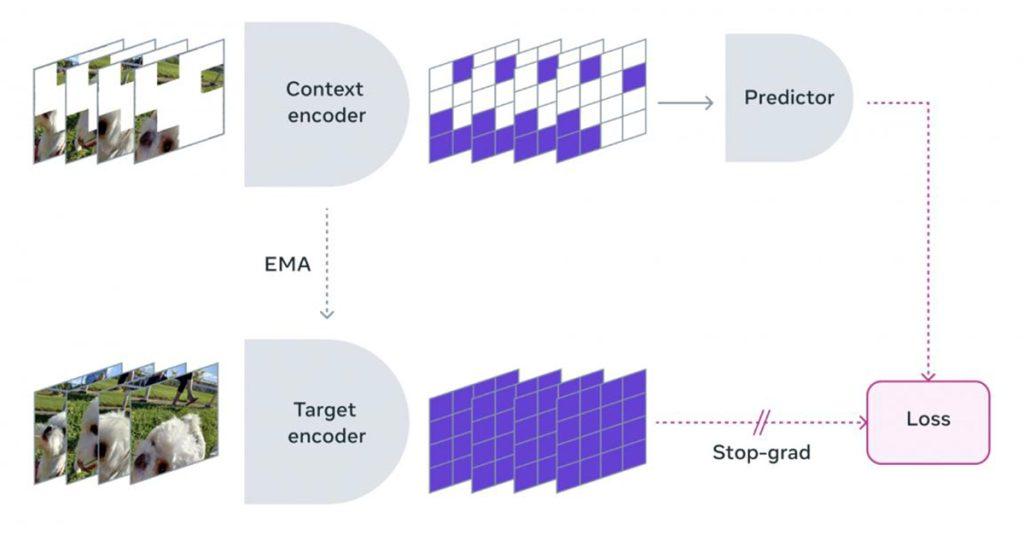
V-JEPA提升對真實內容理解
V-JEPA有能力丟棄不可預測的資訊,使得訓練和採樣效率可提升達1.5到6倍,採用自監督學習方法,研究人員讓模型觀看一系列的影片,使它掌握運作的方式,這些影片會經過遮蔽處理,透過遮蔽大面積影片內容,要求預測器在只有一小部分影片內容中填充缺失的內容,Meta特別制定涵蓋空間與時間的遮蔽策略,迫使模型學習並且發展對場景的理解,進一步預測未來的事件或是動作,進而達到更深層次的理解。
此外,V-JEPA另一個重要創新是凍結評估的能力,模型在預訓練之後,核心的部分不會再改變,因此只需要添加小型專門層就可適應新任務,可以避免傳統模型針對新任務需要全面微調的不便,減少學習新任務的資料和時間要求,讓模型能夠在不同任務中重複使用。Meta會繼續擴展V-JEPA模型,從只處理影片的視覺內容,增加整合音訊實現多模態學習,透過更豐富的上下文資訊,可以加深模型對影片內容的理解。
瀏覽 947 次





