Google發表新模型Lumiere 一次可文字轉生成5秒高品質影片
記者/竹二
Google近日發表全新的文字轉影片擴散模型Lumiere,這是一種可以把文字轉換成影片擴散的模型,採用創新的時空U-Net(Space-Time U-Net,STUNet)基礎架構,可以一次生成真實、多樣且動作連貫的短影片。根據Google官方說法,這種技術可以一次生成完整的影片長度,而不需要經過多次處理。
文字轉影片模型挑戰高,動作無法連貫
近一年多以來,圖像生成模型有長足進步,可以根據複雜的文字提示,生成高解析度且逼真的圖像,但是想要將這些複雜文字轉成影片還是有很高的挑戰,主要原因在於影片中的動作複雜性。
更多新聞:Google最新多模態VideoPoet 可完成各種影片生成任務
目前的文字轉影片模型沒有辦法生成長時間且動作逼真的影片,Google研究人員解釋,因為這些模型通常採用分階段的設計,會先生成幾個關鍵畫面,再用時間超解析度模型,填充關鍵畫面之間的畫面,這個方法雖然在記憶體效率上表現良好,但是在連貫動作上有限制。
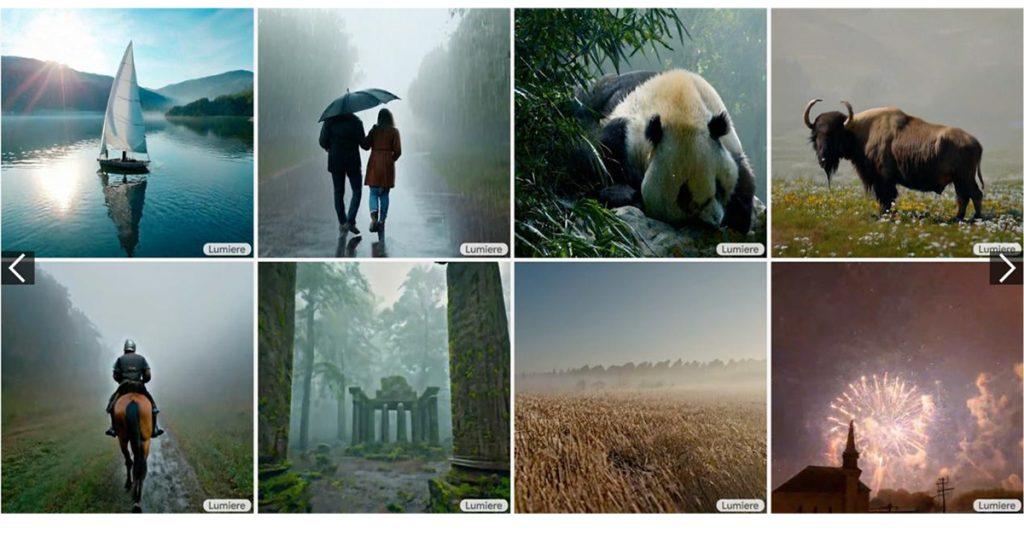
Lumiere一次可生成5秒影片
而Google的新模型Lumiere則是採用不同的方法,他們使用STUNet架構一次性生成完整時間長度的影片,能夠在空間和時間上同時降採樣訊號,在更緊湊的時空進行大部分運算,可以一次可以生成80影格,以每秒16影格來算,可產生長達5秒的影片。研究人員指出,5秒的長度超過大多數媒體作品中平均鏡頭時長。
根據Google的說明,Lumiere是建立在一個經過預訓練的文字轉圖像模型之上,先由基礎模型在像素空間生成圖像的基本草稿,再透過一系列空間超解析度模型,逐步提升這些圖像的解析度和細節。整體而言,Lumiere是一個強大的文字轉影片擴散模型,可以生成高品質且動作連貫的影片,用於多種影片編輯和內容創建任務,像是影片修復、圖像轉影片生成,或是生成特定風格影片等。
瀏覽 695 次