生成式AI成長為何沒有帶動傳統AI普及化?|專家論點【Howie Su】
作者:Howie Su(產業分析師)
ChatGPT 推出近一年後,各家公司現在正忙著採用生成式人工智慧來獲得新的競爭優勢或阻止競爭對手效仿,最近微軟與Open AI的經營權事件可見一般,不過,除生成式人工智慧外,傳統形式的人工智慧又如何呢?人工智慧還有空間容納老式的機器學習嗎?到目前為止,生成式人工智慧普及似乎並沒有引起傳統人工智慧能力的廣泛提升。麥肯錫最近的人工智慧現狀報告指出,2023 年是生成式人工智慧的突破年,三分之一的受訪組織表示他們已經定期使用相關技術:40% 的組織計劃增加對人工智慧的整體投資。但麥肯錫表示,這並沒有對其他形式的人工智慧產生任何外溢效應。事實上,自2022年以來,採用人工智慧工具業者的百分比一直保持穩定,並且應用領域仍然集中在少數業務範圍內。
生成式人工智慧與傳統人工智慧差別在哪?
為什麼會這樣?這樣的現象原因在於,生成式人工智慧與傳統人工智慧有顯著差異:生成式人工智慧主要基於非結構化資料進行訓練,而傳統機器學習主要基於結構化資料進行。而生成式人工智慧猛爆式成長也給企業帶來一定困惑,很多公司過去因為數位轉型,正在嘗試結構化與非結構化資料的處理,人都還沒完全找齊,業務智慧化也還在進行,結果突然間,非結構化資料可應用範疇突然變非常大,很多公司現在的挑戰是,我們應該使用這些資料來做什麼?許多業者可能還沒想好要怎麼把這些非結構性資料變現,或是改變商業模式。多數企業使用生成式人工智慧用於公司內部數據、文字和報告的內部助理,與聊天機器人建立上,但說要改變商業模式形成,或是像微軟、Google這樣具備廣大應用場域的現象倒是還沒出現。
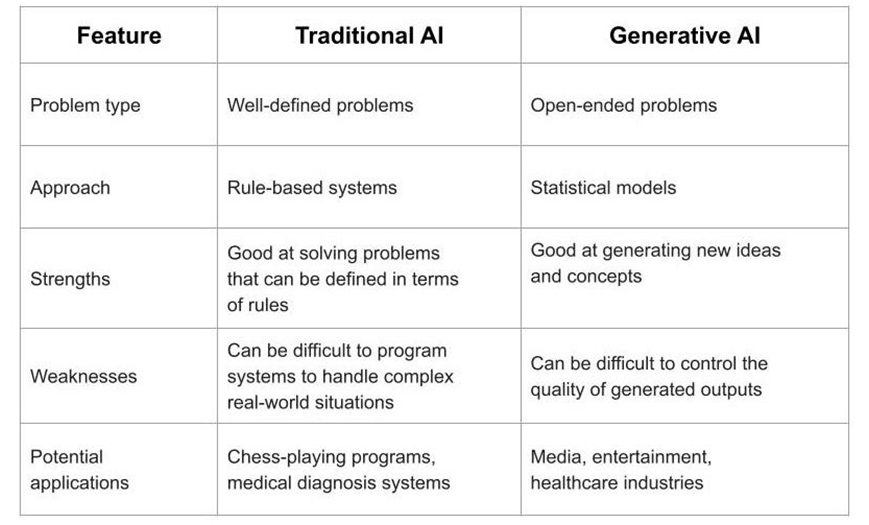
另外,傳統的人工智慧模型大多是客製開發的,相較之下,生成式人工智慧應用程式大多是使用供應商開發的框架建立的,有些供應商提供專有 FM(AI21 Labs、Cohere、LightOn 等)以及開源 FM(Stability AI Hugging Face 等)。這些基礎模型可以使用專有資料進行客製化訓練或微調以用於特殊用途。;同時,生成式人工智慧和傳統人工智慧計畫之間還有其他重要區別。例如,開始使用生成式人工智慧需要較小的前期開發成本,並且可以在幾天內建立起來,傳統人工智慧需要更高的前期成本,並且啟動時間更長。而在技能需求上也有很大差異,在傳統人工智慧中,需要熟練的開發人員從頭開始建立模型,以及大量的資料準備和資料標記工作來訓練模型。但對於生成式人工智慧,模型是預先建立與預先訓練的。最後,傳統的人工智慧用途本質上是分析性的,根據過去的數據預測值或對觀察結果進行分類,相較之下,生成式人工智慧可以產生內容並執行任務,由此產生的應用完全不同,新功能包括程式碼、文字、圖像、視訊、音訊和資料的生成和操作。
兩者怎麼搭配比較好?
並不是說傳統人工智慧將被生成式人工智慧取代,或是進行模型開發的數據科學團隊將變得多餘。生成式人工智慧用例與傳統人工智慧用例有很大不同,實施生成式人工智慧需要改變企業架構、開發週期、新角色和技能。生成式人工智慧並不能解決所有問題,但它有它的空間並帶來新的能力,目前,我們看到的大多是獨立的生成式人工智慧解決方案,但為了充分發揮其潛力,生成式人工智慧最好與傳統人工智慧和現有應用程式結合使用,從 IT 策略和企業架構角度來看,將生成式人工智慧與現有數據、應用程式和自動化平台結合,需要仔細評估應用性。
瀏覽 1,168 次