
語言模型蔚為風潮 OECD打算端出什麼政策因應?|專家論點【Howie Su】
作者:Howie Su(產業分析師)
一場針對AI的監管風暴正鋪天蓋地而來
ChatGPT因其明顯的優勢而成為琅琅上口的名字,與此同時,政府和其他監管機構正在採取措施來遏制潛在風險,由於人工智慧語言模型(LM) 是 ChatGPT 等廣泛使用的語言應用程序的核心,因此值得仔細探討該技術及其對社會的影響。從本質上來說,語言模型的應用相當多樣,包括文本生成、文本到語音轉換、語言翻譯、聊天機器人、虛擬助理和語音辨識等,它們讓電腦能夠處理並生成人類語言,同時使用從基於規則的方法到統計模型和深度學習等技術對大量數據進行訓練,不過問題在於,它們的內部如何運作對多數人而言是不透明的:社會對於它們如何在廣泛的工作中的運作模式、如何輸入到輸出的流程依舊是一頭霧水,這種「黑盒子」的做法引起不小騷動,「如何解釋其運作,以及會造成什麼潛在危害」就變成了當前管理人工智慧的重點,而OECD近期發布相關觀點,似乎能看出一些端倪。
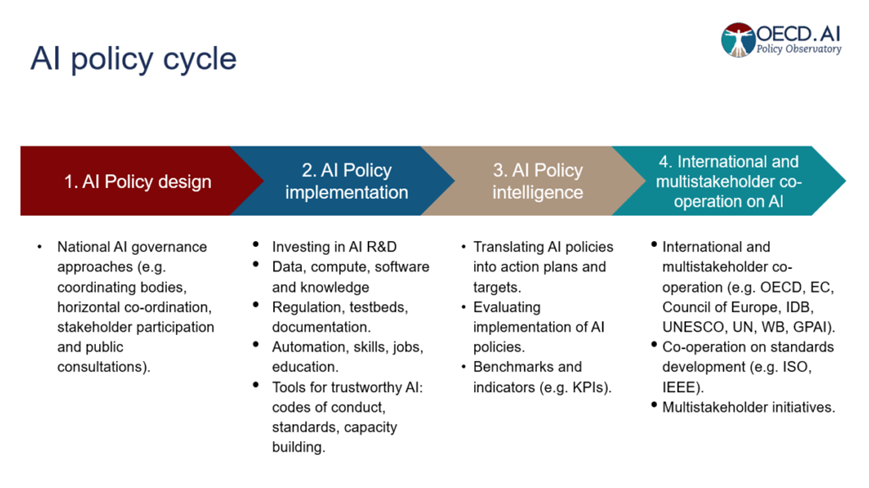
政策制定者陷入良好政策環境將低科技風險的兩難
隨著個人和企業將語言模型整合到其日常營運中,社會大眾開始希望政策制定者需要確保這些變革能夠創新同時又確保安全性,OECD 在2019 年發布人工智慧原則時就指出,「AI在整個生命週期中應保持穩健、可靠和安全,以便在正常使用、可預見使用或誤用或其他不利條件下能夠正常運行,不會造成不合理的風險」。然而,三年後的現在,持續成長的的語言模型卻帶來相關的重大政策挑戰,許多語言模型使用不透明且複雜的神經網路,即使開發者對其內部運作原理以及如何達到特定產出有所了解,在持續的使用下卻也可能造成無法預測與約束的情況,政策制定者必須促使開發人員制定更嚴格風險控制方法和系統標準,以符合應用環境的安全。此外,由於語言模型是「生成式人工智慧」的一種形式,模型根據訓練數據的提示建立新內容,但訓練數據本身可以包括偏見、個人機密資訊與侵犯他人智財權的可能性,使得產出內容的真實性有所疑慮,甚至透過大規模生成假內容來造成真假難辨的「人工智慧幻覺」(AI Illusion)。
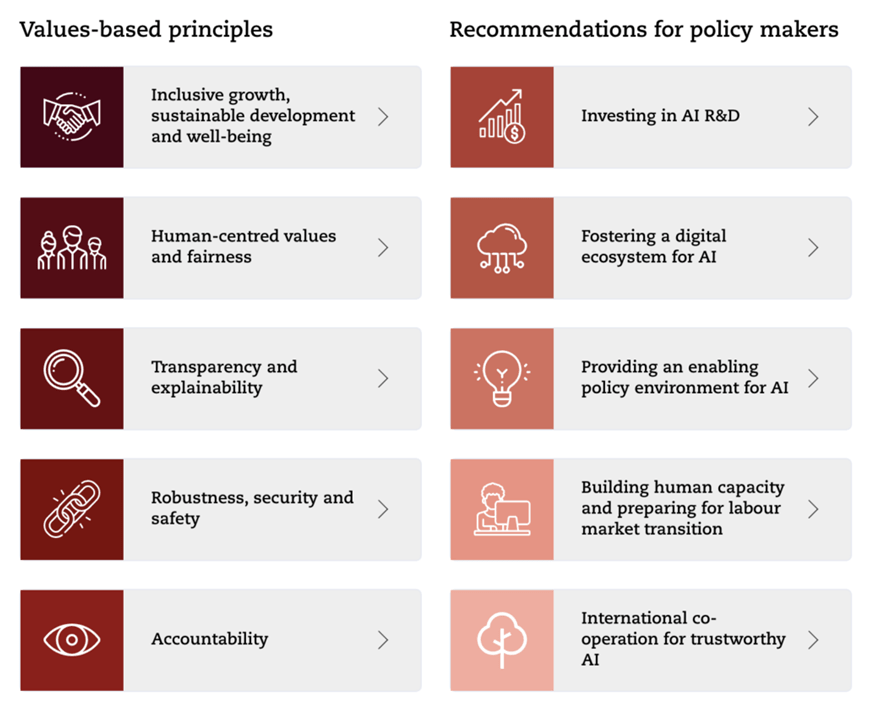
持續的研究有助於降低複雜語言模型風險
開發人員持續的研究與模型調整有助於理解這些複雜的模型並找到風險緩解危機的解決方案,對於許多語言來說,用於訓練模型的可讀文本的可用性依舊有限,最先進的特定語言模型僅使用主要語言,例如英文、中文、法語和西班牙語,少數民族語言國家則遭到遺忘,政策制定者正在促進多語言模型的開發,來促進包容性並避免未來造成文化霸凌。同時,包括政策制定者在內的利益相關者需開始透過合作來探討相關的新型的社會影響與科技風險,合作的形式是在區域和國際論壇上分享最佳實務與危害案例,並製定多語言數據和模型方面的聯合倡議。然而,企業與政府仍然需要製定可行的政策和技術解決方案,以有效降低語言模型和其他類型的生成人工智慧的風險,同時促進其有益的開發和採用,使人工智慧生態系統中的所有參與者都能夠在預防科技災害上扮演關鍵角色。
瀏覽 585 次




