
AI監管大不易?三大難題先解決再說|專家論點【Howie Su】
作者:Howie Su(產業分析師)
想要管理好人工智慧有這麼容易嗎?
近期Open AI被使用者聯手提告,劍鋒直指該公司搜集大量個人數據做為訓練人工智慧,同時也有侵犯智慧財產權之虞,提出30億美元賠償金額,而富爸爸微軟也連帶遭殃,的確,從個人到企業都逐漸發現,這種公開的大型語言模型可能讓個資與商業機密外流,一陣監管聲音在社會中發出,各國政府與民間團體紛紛提出不同的監管框架,希望能讓技術發展不要帶來「文明毀滅」,2023年5 月,Google執行長Sundar Pichai宣布與歐盟達成協議,在歐盟人工智慧法案實施之前訂定自願行為標準「人工智能協議」,避免受到無情裁罰;但Open AI創辦人Sam Altman卻公開反對歐盟懸而未決的人工智慧法規,並警告:「我們將盡力遵守,但如果我們不能遵守,我們將停止在歐洲營運。」,彰顯出在技術管理上的分歧,事實上,當前要如何管理好人工智慧,至少有三大問題要先解決。
難題一:技術發展太快了
從時間軸來看,2016-2023年的人工智慧發展速度可說是突飛猛進,2016 年,Google因其 DeepMind 人工智慧模型在中國圍棋比賽中擊敗人類冠軍而成為頭條新聞,該公司立即推出了自己的人工智慧聊天機器人 Bard。Meta 首席執行官Mark Zuckerberg對員工表示:「我們最大的一項投資是推進人工智慧並將其構建到我們的每一款產品中。」 2023年3月,OpenAI 就推出 GPT-4,這是為 ChatGPT 大語言模型 (LLM) 的最新版本,OpenAI 聲稱該模型在各種任務上「表現出了人類水平的表現」,並獲得大量使用者,與此同時,多家規模較小的業者也在開源代碼的幫助下也加入了人工智慧的競賽。
而在工業時代,政府的監督模式一直遵循管理大師泰勒的說法,這種「泰勒主義」宣揚「只有將法規強制性標準化」,才能取得有效的結果,而這種管理技術之所以有效,很大程度上是因為工業創新和採用的步伐較慢,同樣較慢的速度也使得這種模式能夠透過監管法規有效實施。但現在就不同了,工業革命建立在取代和/或強化人類體力的基礎上,而人工智慧旨在取代和/或增強人類的認知能力,將前者的監管需求與後者的監管需求混淆將無法跟上數位時代的變化,甚至損害消費者和公司的利益,這是許多政府在監管時遇到的頭痛問題。
難題二:資訊越來越真假難辨
人工智慧可能提升錯誤資訊的數量與氾濫程度。到目前為止,平台業者儘管當前是新聞與各種資訊的主要來源,但未能遵守新聞標準,Meta的Sheryl Sandberg認為「從本質上講,我們是一家科技公司,我們僱傭工程師。我們不僱用記者。」,意即不想受到傳統媒體行業的規範,但又想取代傳統媒體業者,但是,這種做法可能會加劇侵犯個人隱私、擴大非競爭性市場、操縱個人資訊與傳播仇恨言論、編織謊言等問題,而現實情況是,這些危害目前在網路上十分猖獗,且難以阻止。
難題三:到底是誰來監管?
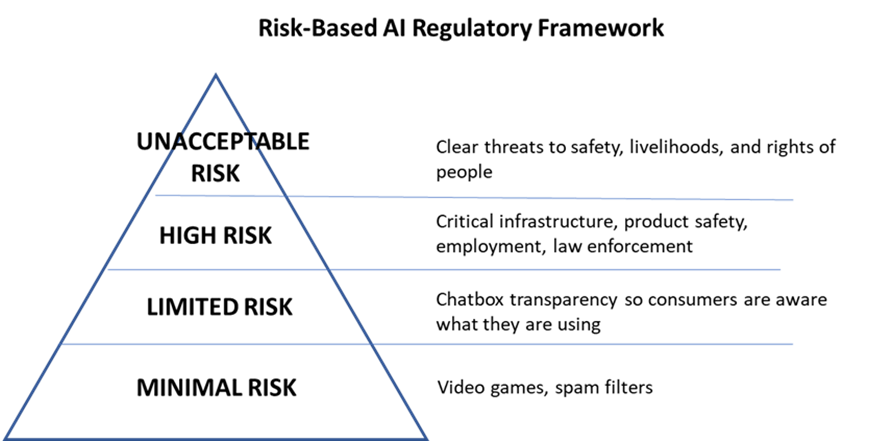
迄今為止,在數位經濟中,許多規則是由創新者制定的,而非政府,這在很大程度上是因為政府未能做到這一點,由科技業者製定的規則有利於企業版身,社會普遍認為需要訂定人工智慧政策,但問題是誰來製定這些政策?政府?政府加企業?政府加企業加民眾?由於利害關係人太多了,單是要制定這些政策就讓人相當頭大。有不少聲音提出需要一個獨立機構來執行,這種監督必須側重於減輕技術的影響,而不是對技術本身進行微觀管理,歐盟應該是目前比較好的例子,該機構監督人工智慧的第一個部分是首先要認識到,由於數位技術的影響並不一致,因此對這些影響的監督並不適合用一刀切的方法,為了讓管理更有效,歐盟對人工智慧進行了多層的分析,確認在不同影響下應該有分級的管理方式。
瀏覽 14,539 次





