
用聖經譯本訓練AI語音模型 Meta可支援1107種語言
記者/竹二
Meta近期在人工智慧的訓練上動作頻頻,近日他們又大幅推進語音辨識技術,釋出的單一多語言語音辨識模型MMS(Massively Multilingual Speech)模型,能夠處理1107種語言,在語音和文字間轉換,同時還能辨識超過4000種的口說語言,這個數量是目前已知技術的40倍。
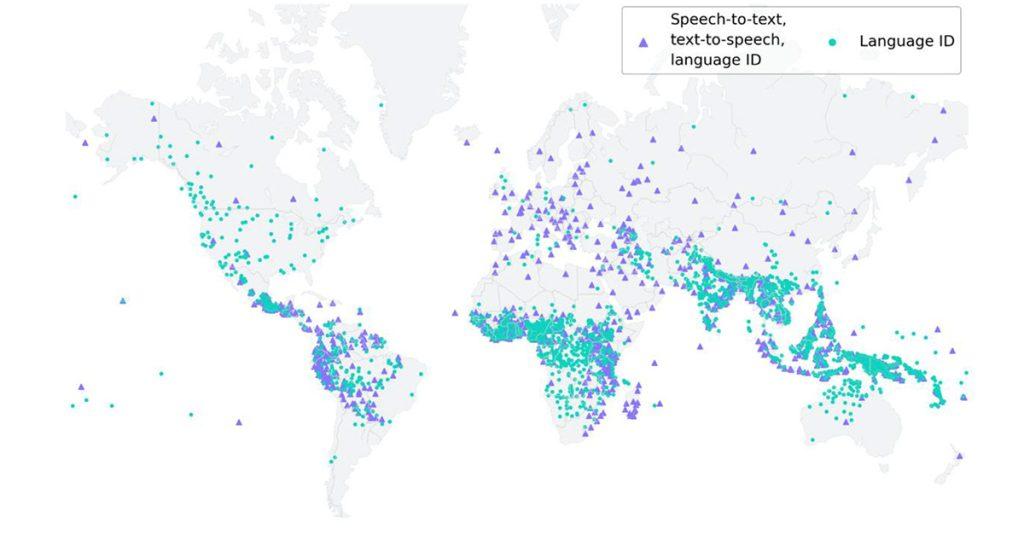
不過,為了要訓練出能夠辨識大量語言的模型,Meta遇到不少困難,首先遭遇到的就是收集各種語言的音訊資料的問題,因為目前最大的語音資料集,也頂多涵蓋100種語言而已,因此Meta的研究人員想到一個克服的方法,就是利用聖經等宗教文本,這些文本已被大量翻譯成各種不同的語言,而且翻譯本也被廣泛用在文字語言翻譯研究上。
除此之外,這些宗教文本翻譯也都有公開的錄音,研究人員利用這些錄音創建出1100多種語言的資料集,每種語言平均有32小時的錄音資料。除了聖經之外,還有許多基督教宗教讀物也可以被拿來訓練模型,這讓Meta得以將可用語言數量擴增到達4000多種。
根據研究人員的說法,經過他們的分析,雖然這些錄音資料主要都是男性的聲音,但MMS模型處理男性和女性聲音的效能表現一致,且雖然訓練資料內容來自於宗教,並不會使模型產生更多的宗教語言。
Meta官方表示,目前地球已知有7000多種語言,但許多語言正在消失,更強大的語言技術將有助於保護這些語言,他們現在開源MMS模型以及程式碼,以供研究社群能夠以這些基礎進行後續研究。
瀏覽 912 次





