
要投胎9,415次才趕得上ChatGPT的閱讀量!|專家論點【台灣科技媒體中心】
文章來源:台灣科技媒體中心

議題背景:
OpenAI在今(2023)年3月14日正式推出GPT-4,比起先前的GPT-3.5回答問題更精準,還可以請GPT-4解讀圖片。OpenAI共同創辦人Greg Brockman也用youtube影片示範GPT-4的特點與限制。
英國的衛報也報導,OpenAI表示GPT-4接受了互聯網上大量資料的訓練,因此改進了很多原本GPT-3的問題並且更有創造力,但用戶在使用語言模型輸出的答案時仍應格外小心,建議再人工檢查過內容。
相關資訊:
- OpenAI GPT-4公開資訊:GPT-4
- OpenAI GPT-4預印本平台的技術報告:GPT-4 Technical Report
- 英國衛報:OpenAI says new model GPT-4 is more creative and less likely to invent facts
- CNN新聞:The technology behind ChatGPT is about to get even more powerful
專家怎麼說?
2023年03月16日
國立中央大學資訊電機學院資訊工程學系教授 蔡宗翰
1. GPT-4的優勢和限制分別是什麼?
GPT-4是目前為止最強大的語言模型之一,它的優勢在於,GPT-4現在使用更多的訓練資料和計算資源,能夠更準確地回答問題和生成文字,並減少語言偏見的影響。
此外,GPT-4透過學習大量的文字和圖像資料,獲得更高的創造力和想像力,能生成更有趣和獨特的文字和圖像描述。而且,它也具備解讀圖片的能力,可以從圖像中發掘關鍵資訊並生成相關的文字描述。
值得注意的是,GPT-4必須要有大量的計算資源才能運行和訓練,因此在某些設備上可能會難以實現,且會消耗大量的能源。此外,即使GPT-4的準確性比之前的版本更高,仍有可能出現一些錯誤,因此在使用時需格外小心,並進行進一步的確認。
2. 根據您的研究經驗,GPT-4解讀圖片且生成文字的能力,還可以從哪些方面精進呢?是否需要開發新的演算法,或是給予更多高品質的訓練資料?
目前來看,GPT-4在解讀圖片和生成相關文字方面已經取得了很大的進展。但是,這種技術還存在一些限制和挑戰。例如:
圖像和文字之間的關聯是一個複雜的問題,目前的語言模型在這方面仍存在一定的局限性。為了進一步提高模型的準確性和精確度,需要開發更先進的演算法和技術。
GPT-4在生成文字時可能會編造非事實性的回答,這可能會對使用者造成誤導和負面影響。為了解決這個問題,可以考慮引入更多的事實驗證機制和檢查機制,同時需要給予模型更加高品質的訓練資料。
另外,語言模型的訓練資料可能存在一定的模型偏見,例如性別、種族、文化背景等方面的偏見。為了解決這個問題,需要更加細緻的調整和訓練模型,同時更加嚴格的審查和檢查模型的輸出結果。
總之,為了進一步提高GPT-4的解讀圖片和生成文字的能力,需要進一步探索和研究相關的演算法和技術,同時也需要給予更多高品質的訓練資料和更加細緻的調整和訓練。台灣必須要有資源投入、深耕,以及研究訓練大型語言模型的技術,絕不能只是使用者,才不會在國際AI軍備競賽中落後。遇到有心者利用GPT-4製造假訊息攻擊時,才有能力判別與解讀假訊息。
3. GPT-4讓大眾對人工智慧的期待更高,但也出現許多擔憂,例如人工智慧可能降低造假門檻與成本。您建議我們如何看待最新的AI生成文字技術,以及在使用上有哪些小撇步和注意哪些事項,以降低從GPT-4得到錯誤資訊的機會?
最新的AI生成文字技術,如GPT-4,具有極高的創造力和生成能力,可以幫助我們更快速、更有效地生成各種類型的文字資料。同時,它也存在一些風險和潛在的問題,例如可能會編造非事實性的回答,產生偏見和不當影響,因此在使用上需要特別注意。
以下是我一些建議的小撇步和注意事項,以降低從GPT-4得到錯誤資訊的機會。
檢查輸出結果:使用者在使用GPT-4生成的文字時,應該始終檢查輸出結果,確保其符合事實和正確性。如果有任何不確定或不正確的地方,應該進一步查證和驗證。
確認來源可靠性:如果從網路上獲取資訊,應該確認其來源的可靠性和真實性,避免受到不可靠的資訊和資料的影響。
使用多種來源:為了避免偏見和局限性,使用者應該使用多種來源的資訊,從不同的角度和視角獲取資料,進行綜合分析和判斷。
注意隱私和安全:在使用GPT-4等技術時,需要注意隱私和安全問題,避免個人資料和機密資訊的外洩和損失。
學習和實踐批判思考:最重要的是,使用者應該學習和實踐批判思考,不盲目相信任何一個模型或技術,並且從不同的角度和角色出發進行思考和判斷,確保獲取到的資料和資訊符合事實和真相。
總之,最新的AI生成文字技術,如GPT-4,為我們帶來了許多便利和效率,但也存在一些風險和挑戰。在使用上,我們應該特別注意其限制和潛在問題,並且採取相應的措施和注意事項,確保獲取到的資料和資訊的正確性和可靠性。
國立政治大學傳播學院助理教授 李怡志
1. GPT-4讓大眾對人工智慧的期待更高,但也出現許多擔憂,例如人工智慧可能降低造假門檻與成本。您建議我們應如何看待AI生成的文章,以及如何辨別內容的正確性呢?
一般人因為先會使用Google 才會使用ChatGPT,所以常會以 Google 的概念來看 ChatGPT。Google是一個資料索引目錄,你輸入了關鍵字,索引目錄協助你找到資料。ChatGPT則是學習資料後建立模型,你輸入了提示,他會解讀你的提示之後,給你GPT學會的東西。如果我們將這兩個角色擬人化之後,Google是一個圖書館員,它不會告訴你任何東西,只會幫你找東西。ChatGPT是一個會超級多語言的口譯員,它不會幫你找東西,但是很愛幫你「翻譯」或「轉譯」,也很樂於自己補充。簡單來說,前者是用「查」,後者用「翻譯」。
因為ChatGPT / GPT 是根據自己的學習來生成「翻譯」,如果它越像人(工智慧),記憶就可能越不齊全,因為人的記憶不是查資料庫那樣完整,所以我們要假設 ChatGPT 在事實上是可能出錯的,不能完全依賴它完成封閉型(答案只有對錯的,例如「蔡英文的地址」)的事實寫作。
如果我們看到一篇文章,已經註明利用ChatGPT 或人工智慧工具完成或協作,我們就要假設裡面的事實可能有錯、會腦補。但假如沒有註明,那就跟平常看到任何文章一樣,隨時保持注意,保持懷疑,如果對於內容有任何疑慮,就回頭求助圖書館員。
2. 依據您使用ChatGPT的經驗,如何正確運用它,以及使用上有哪些小撇步和注意事項,可以以降低從GPT-4得到錯誤資訊的機會?
ChatGPT是一個口譯員,不是圖書館員,所以一定會出錯,所以我們盡量不讓它獨立產生封閉知識型的內容(例如李白的字、號與祖籍)。使用 ChatGPT 比較好的方式是讓它好好地「翻譯」,讓它提供開放型的內容。也就是說,如果內容有明確的「是非對錯」,最好不要完全依賴它,但如果答案只有「好壞高下」,那麼我們可以開始練習如何使用它。
ChatGPT是一個人工智慧工具,意思是可以理解人話、說人話。但我們也知道,與人溝通向來不簡單,特別是ChatGPT 看不到你的表情,也不知道你提問的脈絡,所以你得講更清楚,特別是規範ChatGPT的產出。
有一個簡單的模型可以讓我們更清楚地協助ChatGPT如何溝通,學者 David Berlo 曾提出 SMCR 模式,將溝通拆解成:傳播者( Source)、訊息 (Message)、媒體(Channel)及接受者(Receiver)四塊。[1]
例如我想請 ChatGPT 寫一篇文章「介紹如何使用ChatGPT寫一篇文章」(本文不是這樣寫出來的),如果真的這樣問,「轉譯」出的結果可能很普通。但我們重新限制後,可以說:
請以傳播學者的身分(Source),
針對人文社會科學的大學生(Receiver),
寫一篇文章介紹如何使用ChatGPT寫文章,不要太技術性,語氣親切(Message),
刊登台灣科技媒體中心的Facebook上面(Channel)。
這樣清楚的說明,就可以讓 ChatGPT「轉譯」出更好的結果。
國立政治大學應用數學系副教授兼學務長 蔡炎龍
1. GPT-4的優勢和限制分別是什麼?
目前看起來,OpenAI訓練GPT-4和GPT-3在文字上應該是運用相同的訓練資料。而GPT-3(ChatGPT)大概「看」了正常人要花超過9,000輩子[註1]才能看完的資訊。也就是說我們讀過的資訊數量遠遠不及GPT-4 讀過的,因此GPT-4和GPT-3都知道比我們更多的資訊。另一方面來說,GPT-4比GPT-3更優秀的是能一次看超過25,000個字,這比GPT-3大約只能看2,048個字好非常多。
之前以GPT-3(更嚴格說是 GPT-3.5)為底的ChatGPT,一次其實不能看那麼多字。於是,長一點的文章,要它作摘要就無法做得那麼好,寫一個報告前後風格有時會有差異,還有在討論事情,方向突然有點改變等等。這主要都是因為GPT-3能看的字數限制。
GPT-4的限制,最主要來自它其實只是「用前一個字預測下一個字」這樣的模型。雖然實際上是用一種叫transformers的架構,我們可以想成是「看完前面若干字,再預測下一個字」的模型。因為前面說到GPT-3一次輸入是2,048個字,所以大概最多看前面兩千多個字,再合理預測下一個字是什麼。
GPT-4只是用神經網路的原理訓練後,計算出文句。只是它真的看過太多資訊,所以可以推出好像非常合理的文句。但其實它沒有意識、沒有情緒,單純是經訓練後算出來的。
2. 根據您的研究經驗,GPT-4解讀圖片且生成文本的能力,還可以從哪些方面精進呢?是否需要開發新的演算法,或是給予更多高品質的訓練資料?
簡單的說,GPT-4的重點不是它還能更強,而是我們現在就可以怎麼使用它。
如前面所說,GPT-4生成文字,只是「前一個字預測下一個字」的模型,使用的是transformers的技術。這種模型其實transformers之前就已經存在,所以GPT-4技術本身不能算是重大突破。反而大家發現,原來這麼「原始」的方式,就能做到這麼多東西。在這之前,AI 專家們曾用各種「高級」的演算法去做許多東西,但現在發現其實沒有GPT-4那麼好。
另一方面來說,這種單純由前面的一些字去預測下一個字的模型,只是依過去訓練的經驗,覺得放哪個字合理,不是真的基於事實。舉例來說,如果是一個名人,GPT-4可能生成的文字會合理一點。但如果不是位名人,比方說請 GPT-4介紹「政治大學應用數學系的蔡炎龍老師」,它會知道政大是在台灣的一所大學,但因關於蔡炎龍的資訊太少,他就會依是應用數學系的老師,「合理」推出一堆文句通順但並非事實的文句。
要改善這樣的問題,基本上是困難的。Microsoft Bing使用的方法是讓 ChatGPT有搜尋的能力,這是其中一個改善的部份。另外其實更合理的是,既然GPT-4最大特點不是說出完全符合真實情況的東西,那為何不由使用者提供呢?我們很容易發現,如果提供基本資訊,ChatGPT就會幫我們生成相當好的文章。很多專家也發現,我們可以和ChatGPT「討論」一些概念,ChatGPT有時說的部份是錯的,你可以糾正它,它就會產生更好的文字。
這件事Microsoft執行長納德拉(Satya Nadella)用了一個很精確的詞,那就是GPT-4這類的模型,是我們的「對話型智慧代理人」(conversational intelligent agents)。這代理人的意思是,它功能多好,其實是我們人類的責任。也就是你越會用它,它就能發揮越多的功能。
3. GPT-4讓大眾對人工智慧的期待更高,但也出現許多擔憂,例如人工智慧可能降低造假門檻與成本。您建議我們如何看待最新的AI生成文本技術,以及在使用上有哪些小撇步和注意哪些事項,以降低從GPT-4得到錯誤資訊的機會?
綜合前面所說,要讓GPT-4產生有用、正確的東西,是使用者的責任。文字生成模型它並不是有意識的提供不正確的資訊,所以刻意要造假消息的,用GPT-4不一定能更快速造出一個人要的假消息。這說不定反而會讓大家更認為,堅持把關文字的媒體、出版社、或知名人物才是值得信賴的。相反的,照片、影片和聲音,反而不會再被大家認為是「有圖有真相」,我們可能要即早思考如何因應。
和文字一樣,或許之後有公信力的人或機構發佈的照片影音等,大家才可以相信。另一個可能是需要讓可以錄影的相機、手機把認證訊息放入照片或影片中,證實真的是直接用這些機器拍下、沒有改造過。
國立臺灣師範大學圖書資訊學研究所特聘教授 曾元顯
1. GPT-4的優勢和限制分別是什麼?
GPT-4是由GPT [1]、GPT-2 [2, 3]、GPT-3 [4]逐漸演化而來的。
GPT是Generative Pre-trained Transformer(生成式預訓練轉換器)的簡稱,其中,「生成式」代表它可生成文字做為輸出的資訊,預訓練代表它經過大量資料的事先訓練,轉換器Transformer則是人工神經網路的一種架構,可以接受一段文字做為輸入,將其轉換成一串數值向量,使得類似的概念,有相似的向量,再進而生成相同主題的文字。
繼2017年Transformer被提出來後,OpenAI公司基於Transformer的神經網路架構以及預測下個字的訓練方式,於2018年6月提出GPT模型。由於成效良好,OpenAI公司將模型加大,於2019年2月提出可以根據人工撰寫的前導文輸出完整文章的GPT-2,2020年5月提出更大型且可依照前導文指示完成多項任務的GPT-3。雖然GPT-3在語言理解與生成方面已屬不凡,但其生成的內容不見得非常符合使用者的意圖,OpenAI遂在2022年1月發表更能符合使用任務的InstructGPT(GPT-3.5)[5],並於2022年11月底提出可跟使用者對話並依照指示生成回應的ChatGPT [6],近期則在2023年3月發表除了接受文字指示外也能接受圖片做為輸入的GPT-4模型[7]。
GPT系列的模型越來越大,訓練資料也越來越多,接受的輸入資訊也越來越長。從一開始GPT只使用到數千萬個參數,GPT-2使用15億個參數,到GPT-3使用到1750億個參數,但OpenAI並沒有透露GPT-4的模型大小,推測應該不會比GPT-3更大(因為更大需要更久的推論和執行時間),但可能用更多資料訓練得更久(因為Meta AI的研究指出,較GPT-3小的模型用更多訓練資料、訓練更久,可以得到跟GPT-3類似甚至超越的成效[8])。
因此,GPT-4的優勢,有幾項:
- GPT-4可以接受更長的輸入,最長到32K(差不多53頁的文字),比GPT-3長16倍,亦即可以理解更長的文章,回應出更長的文字。
- GPT-4的文字理解與生成能力更好,特別是在專業與學術領域,比GPT-3更強。例如,GPT-4在模擬的律師考試方面,其成績已達前10%的程度,而GPT-3僅能達到後10%的程度。
- GPT-4除了可以接受文字的輸入外,也可以同時接受圖片做為輸入,理解後再以文字回應。而GPT-3僅能做到文字輸入與文字輸出。
- 更具可操縱性(steerability),亦即比前一代更易於有效的規範GPT-4回應的風格與定義GPT-4的任務。
GPT-4的限制跟其前一代一樣,仍舊會有無中生有、推理錯誤、各種偏見(如性別、種族、職業等偏見)、不理解訓練資料之後發生的事物(訓練資料只到2021年9月的網路資料)。因此,在高風險的任務上,使用仍須小心,必須盡力求證。儘管如此,GPT-4回應出事實的能力比其前一代高出40%。
2. 根據您的研究經驗,GPT-4解讀圖片且生成文本的能力,還可以從哪些方面精進呢?
雖然「看圖生文」的研究已經取得不錯的進展,但與大型語言模型如GPT-4的整合仍不多見,而且相關的評測資料較少、主題範圍尚未全面,再加上目前OpenAI釋出的訊息有限,因此難以完整判斷GPT-4解讀圖片後生成文本的能力。
3. 是否需要開發新的演算法,或是給予更多高品質的訓練資料?
編造非事實的回應,是這類大型語言模型難以根除的現況。
GPT系列的神經網路,包含GPT-3、GPT-4,其基礎模型是以自我監督的方式訓練出來的。亦即,只要蒐集品質良好的大量語料,不必進行任何的人工標記與判斷、不需用到文法規則,輸入語料中的每一個文本,如下圖一之輸入:「人之初,性本…」,並將該句子的下個字當作輸出目標,如:「之初,性本善…」,然後要求GPT進行生成預測。
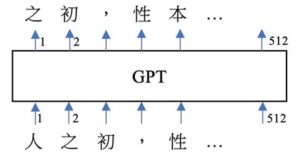
若相對應位置的字詞預測錯誤,就調整參數(以倒傳遞誤差的方式,按梯度下降法調整參數[9])。
因此,究其內部,GPT這類模型只是上千億個小數點參數,在Transformer 神經網路架構下進行運算,就可以得出人類語言的文字順序,完全沒有用到文法規則,沒有用到符號化的知識庫或是資料庫。
觀察GPT的輸出,它已經能理解語言,甚至具備語感,錯字比人類低,對於讀過的豐富主題,講得頭頭是道,非常神奇。
GPT對文句「移花接木、再加潤飾」的能力超乎常人,但還是會生成錯誤的資訊。大家使用時,仍得謹慎。
純粹的GPT模型裡面,沒有用到任何符號式的知識或是人類寫的離散式的規則。語言文字的知識規則,已經被 GPT 轉化成大量數值計算的連續性規則。這種連續性的知識表達方式,可以非常便捷、有效的內差(interpolate)出各種知識的變化,甚至於外插(extrapolate)擴增GPT從未看過的知識。這種知識表達方式以及其運算的能力,是這一波AI大幅成功的主因之一。
GPT-3.5、GPT-4進一步用到人類導師的導引以及強化學習的方式加以訓練,用以抑制較差的輸出、獎勵較好的回應。但基本上,GPT-4仍有可能輸出無中生有、偏見、甚至錯誤的訊息。試想,我們可以要求ChatGPT、GPT-4依照我們的劇情指示,生成劇本。當這個劇情是天馬行空的想像,甚至要闡明什麼是偏見、謬誤、惡形惡狀時,ChatGPT可以生成這樣的劇情。也就是說,誤導、偏見的資訊並沒有從ChatGPT、GPT-4中刪除,只是被抑制,但仍然可能由某種提示被引導出來。
由上可知,編造文句是GPT的天性,此編造的文句非事實,是我們不要的,但在某些場景下是我們要的。
4. 有哪些研究可以降低GPT-4對社會的負面衝擊?
最近有些研究,某種程度上可以偵測AI生成的文句。例如文獻[10-11]微調了 RoBERTa的模型並釋出程式,其識別GPT-2模型生成的網頁時可達95% 的準確率。其他還有許多研究在協助偵測GPT生成的文字[12-15],協助辨別是否有錯用AI文字而有欺騙、造假、不公平的情事,以降低這波AI帶來的社會衝擊。
註釋與參考資料:
【李怡志】
[1] Berlo, D. (1960). The process of communication: an introduction to theory and practice, Holt, Reinhart and Winston, New York.
【蔡炎龍】
[註1] ChatGPT 算了一個人一生中能讀多少字,而GPT-3模型看了4990億個字,依此計算得到一個人要花超過9,000輩子才能看完GPT-3看的字量。

【曾元顯】
[1] Improving Language Understanding by Generative Pre-Training, https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[2] Better language models and their implications, https://openai.com/research/better-language-models, February 14, 2019
[3] Language Models are Unsupervised Multitask Learners, https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[4] Language Models are Few-Shot Learners, https://arxiv.org/abs/2005.14165, 2020-05-28.
[5] Training language models to follow instructions with human feedback, https://arxiv.org/abs/2203.02155, 2022-03-04.
[6] Introducing ChatGPT, https://openai.com/blog/chatgpt, 2022-11-30.
[7] GPT-4, https://openai.com/research/gpt-4
[8] LLaMA: Open and Efficient Foundation Language Models, https://arxiv.org/abs/2302.13971, 2023-02-27.
[9] Rumelhart, D. E., & McClelland, J. L. (1986). Parallel Distributed Processing, Vol. 1: Foundations. Cambridge, MA: MIT Press.
[10] Jawahar, G., Abdul-Mageed, M., & Lakshmanan, L. V. S. (2020). Automatic Detection of Machine Generated Text: A Critical Survey (arXiv:2011.01314). arXiv. https://doi.org/10.48550/arXiv.2011.01314
[11] Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., & Wang, J. (2019). Release Strategies and the Social Impacts of Language Models (arXiv:1908.09203). arXiv. https://doi.org/10.48550/arXiv.1908.09203
[12] ZeroGPT:https://www.zerogpt.com/。
[13] DetectGPT:https://detectgpt.ericmitchell.ai/。
[14] OpenAI 自己做的 AI文字偵測器:https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text。
[15] Data Portraits: Recording Foundation Model Training Data, https://arxiv.org/abs/2303.03919, 2023-03-06.
版權聲明
本文歡迎媒體轉載使用,惟需附上資料來源,請註明台灣科技媒體中心。
瀏覽 5,048 次





