
Google建構YouTube通用語音模型 可辨識100種語言
記者/竹二
Google曾表示,未來將要建構一個能夠支援1,000種語言的機器學習模型,主要用於YouTube,近日釋出了階段性研究成果,通用語音模型USM已經能夠支援100種語言。
相關研究人員表示,傳統的監督式學習方法欠缺可擴展性,想要將語音技術擴展到更多的語言,需要有足夠多的資料訓練高品質模型,過去資料準備的常見方法,要以人工手動標記音訊資料,是非常耗時且昂貴的過程,再加上對於缺乏資源的語言,難以收集足夠的訓練資料,而自我監督式的學習,反而可以利用純音訊資料,因此更能達到擴展至數百種語言的目標。
這款Google的通用語音模型就是使用自我監督式學習,運用大型未標記的多語言資料集預訓練模型編碼器,並使用較小的標記資料集進行微調,讓模型能夠辨識缺乏資源的語言,通用語音模型具有20億參數,使用1,200小時的語音和280億條文句進行訓練。
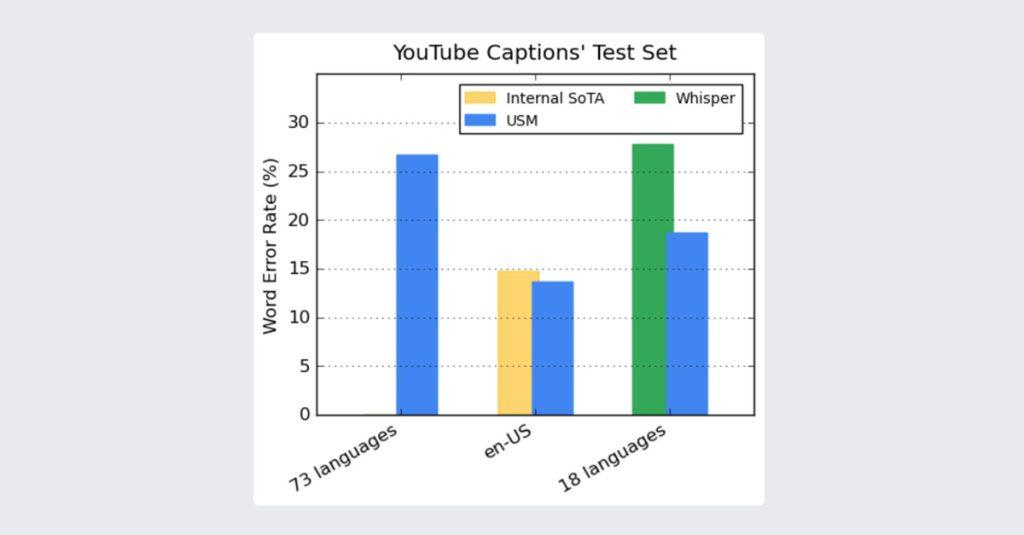
通用語音模型主要用於YouTube,可對英語和漢語執行自動語音辨識,還能辨識資源缺乏的阿薩姆語、馬達加斯加語和宿霧語等,目前已能夠對100多種語言執行自動語音辨識。
據了解,通用語音模型在其中的73種語言,平均每種語言的訓練資料不到3,000小時,卻已經實現了低於305的單詞錯誤率,這是Google過去從未達到的成果。目前在各種公開的資料集測試,像是CORAAL、SpeechStew和FLEURS,通用語音模型的單詞錯誤率都較低。
瀏覽 589 次





