
微軟VALL-E只需3秒模擬真實聲音 恐成詐騙利器
記者/陳士勳
微軟新的AI模型「VALL-E」帶來新革命,用戶僅提供3秒鐘的音訊,該模型便能模擬本人說話的聲音、語調及說話時的情緒,甚至連音訊背景的「聲音環境」,也能如法炮製,不過如此功能可能被詐騙人士利用,微軟也開發檢測模型,區分該音訊是否經由VALL-E合成,且制定相關AI原則,避免惡意濫用。
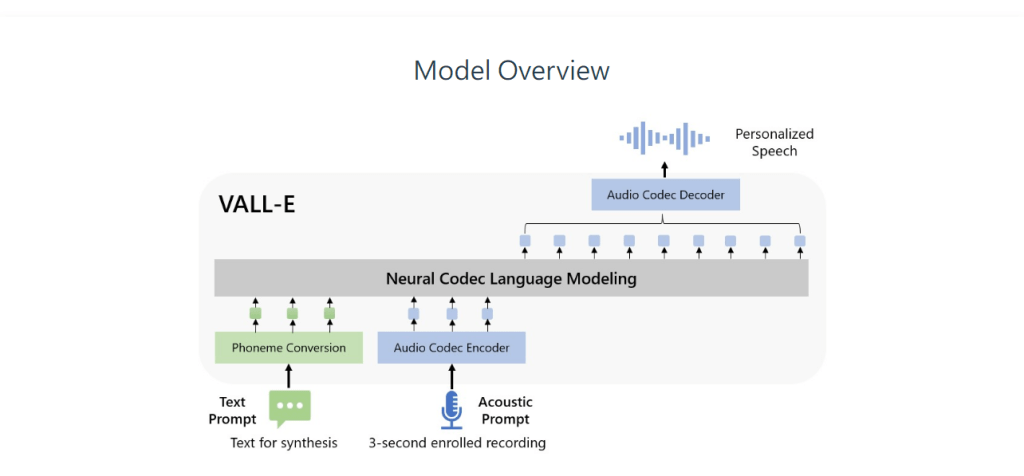
微軟研究人員表示,VALL-E基於Meta在2022年10月發表的EnCodec技術,所打造而成的「神經編碼解碼器語言模型」,不同於一般透過操控波形合成語音的常見文字轉語音法,而是從文字與聲音提示,產生個別音訊編碼解碼器程式碼,並透過EnCodec,將資訊分解成可稱為「標記」(Token)的個別元件,進而分析人類發音。
微軟指出,VALL-E能對比訓練資料與「學會」的聲音,只要上傳3秒鐘的音檔,即可複製該語調來說話,為了建構VALL-E的語音合成能力,微軟採用內含7千多人、約 6 萬小時說話內容的LibriLight音訊庫訓練,以提供用戶數十個的AI模型執行範例音訊。
微軟強調,由於VALL-E還可模擬音訊背景的「聲音環境」,簡單來說,如果音訊來自不同場合,像講電話、搭乘交通工具、開車等背景,接聽者會感覺音訊是經該背景所傳遞而來,因此,微軟準備應對的檢測模型,辨別真假音訊,預防VALL-E成為詐騙和網路攻擊的武器。
瀏覽 911 次





