
歐洲人工智慧發展落後美、中,要如何扳回一城?|專家論點【Howie Su】
作者:Howie Su(產業分析師)
主要國家企業積極開發NLP模型,獨缺歐洲
雖然普丁是俄烏戰爭的導火線而被西方國家敵視,但他在2017年講的一句話卻身受外界認同:「哪個國家在發展人工智慧領先將能稱霸全球」。從近期事件來看,微軟計畫加碼投資OpenAI達100億美元,以將ChatGPT、GPT-3、DALL-E 2等人工智慧模型嵌入Azure服務,提升商業化速度;此外,其他美國科技業者如Google(Gopher)、NVIDIA(Megatron Turing NLG),中國大陸的企業百度(Ernie 3.0 Titan)、華為(Pan Gu)、浪潮(Yuan 1.0)也紛紛釋出其他AI模型,甚至韓國的Naver(HyperClova)、以色列的AI21 Labs(Jurassic1-Jumbo)也加入這場前瞻技術競爭—但卻沒有一家歐洲業者在自然語言處理(NLP)模型開發達到重大突破,雖然在2021年德國新創Aleph Alpha募得2,800萬歐元並嘗試打造如GPT-3的模型,但目前尚未成功。
歐洲發展人工智慧落後的四大衝擊
根據Future of Life Institute在2022年11月發布的“Emerging Non-European Monopolies in the Global AI Market”報告指出,歐洲因企業缺乏足夠的資金、運算資源,與數據,在AI模型發展上居於劣勢,導致歐洲企業未來可能被迫採用其他國家企業設計的人工智慧系統,而這將帶來數個負面影響,第一為付出額外使用溢價,墊高企業科技投資成本;其二為語言使用限縮,AI模型可能僅以中文或英文版本釋出,造成部分國家業者使用效率降低;第三為現在各國力推科技自主,雖然當前焦點都放在半導體居多,但人工智慧也成為戰略性技術的一種,同時在兩者取得優勢才能確保技術能自給自足;最後為錯失432美元的商用市場,影響甚巨。
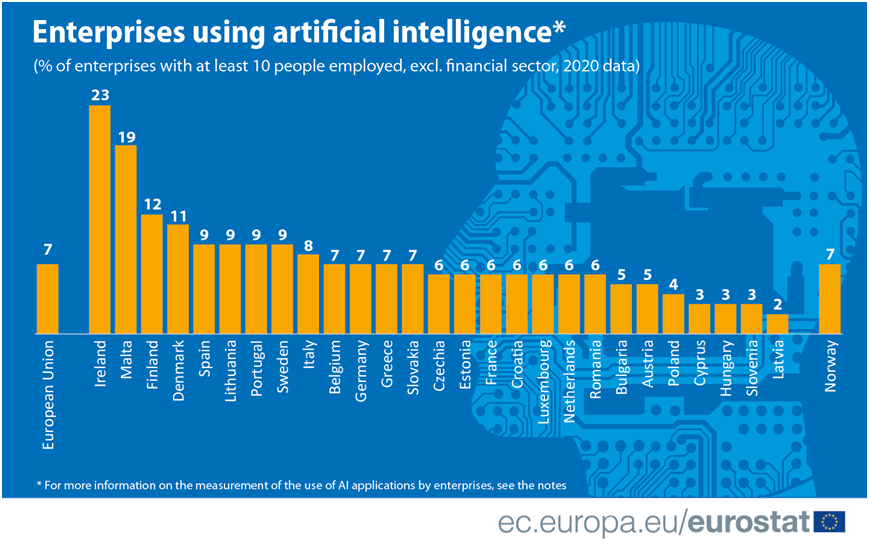
若細看原因,其中之一為在英國脱歐後,坐落歐洲的頂尖學術機構難以為「工業4.0」及「工業新法國」等發展計劃提供充足的人才和研究,雖然歐盟近年著力推動「Erasmus Mundas」教育策略,投注資源培育科研人才,但其資訊科技教育水平仍然落後其他國家,加上歐盟是由28個成員國組成的跨政府機構,文化差異在各成員國之間可謂相當常見,如何平衡各國利害關係來取得對單一市場支持,往往是歐盟企業的一大難題。
歐洲積極投入大型AI模型建置
為彌補該巨大差距,由德國人工智慧協會正在展開一項稱為「大型歐洲人工智慧模型(Large European AI Models,LEAM)」 的計劃,旨在縮小與美國和亞洲競爭對手的差距,獲得大型業者如SAP、Continental、Bayer、Merck的支持,該計劃至少耗費3.5 億歐元投入大型AI模型研發,目的為打造一台能夠運用多達 2,000 億個參數的超級模型。雖然模型的性能不能僅用參數數量多寡來判斷,甚至有分析指出鑰匙模型越精確,反而需降低參數數量,但參數的數量不僅展現一家企業在人工智慧的投入,也是一國國力的展現:OpenAI 的 GPT-3 的參數數量為1,750億個,而北京人工智慧研究院的「悟道 2.0」,已經使用1.75兆個參數作為訓練;相較之下,德國業者Aleph Alpha僅使用700億個參數。
當然,如此的投入並非全無風險,如前所述,研發超大型模型需耗費龐大資金,Lambda Lab預測如GPT-3的訓練成本高達4,600萬美元,研發成本為2760萬美元、硬體設備投入需10-15萬美元,而這還不包含用電、冷卻、維護的成本。另外,模型是否能夠應用在企業的商業模式也是未知數,尚需觀察。
資料來源
- Europe Is Lagging Behind In Developing Large AI Models
- Emerging Non-European Monopolies in the Global AI Market
瀏覽 1,074 次





