
如何讓『資料分析師』與『專案企劃人員』有效率合作?

文/傑瑞
其實你可以從Scrum框架借一些靈感!
傑瑞最近又接到一個有趣的任務:協助人資部負責徵才的單位建立「數據驅動的招募流程」,要想辦法幫助他們跟資料分析人員一起有效率地溝通討論與合作產出。其實這樣的命題在大企業裡面屢見不鮮,只要是業務涉及上下游承辦關係就容易產生溝通障礙,例如PM要與IT人員合作開發產品功能、PM要與行銷人員合作產出銷售DECK、PM要與作業經辦合作寫出流程SOP、PM要與客服人員合作產生用戶Q&A...(有沒有覺得PM的溝通力好重要XD) 而目前的產業趨勢為數據導向,公司可以利用數據來優化流程、協助決策、預測銷售等等。所以如果能讓組織的大腦(懂業務邏輯的人)與手腳(會採集資料的人)合作順暢,公司利用既有數據所創造附加價值(增加收益、降低成本)的潛力就愈大。 =====================================================(我是分隔線) 所以這篇文章傑瑞要來分享: 1.數據驅動的最高指導原則 → 以終為始 2.如何不著痕跡借用Scrum的元素來設計工作坊幫助做事雙方聚焦需求以及分解任務
數據只是output,決策才是outcome
通常這種上下游承辦關係的討論場合,傑瑞開場習慣先做一件事:
讓雙方搞清楚這裡沒有誰是老大:)
PM雖然懂業務邏輯,但沒有資料分析師幫忙做出數據也只能說得一口好書。資料分析師雖然懂運算技術,但如果沒有PM提供業務邏輯背後的運算(加值)規則也只是空有一身本領。所以在「數據驅動」這樣的命題裡,PM要多分擔業務邏輯的定義與梳理,而資料分析師則是負責數據採集的效能與效率,不是說上游的部門就能發號施令而下游的部門只能聽命行事喔。
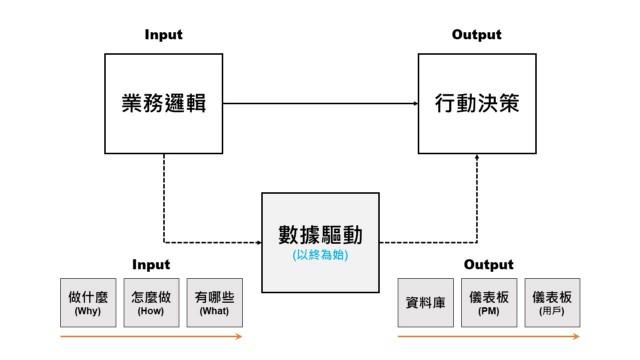
搞定雙方的權利義務之後,接著說明討論「數據驅動」的正確步驟。PM要知道,就算沒有資料分析師將數據集中化/圖像化/自動化,PM以往還是能根據腦袋裡的業務邏輯來做決策,只是自己在資料採集的過程中不那麼方便而已(資料散佈在多個系統/需要另外製作成圖表轉譯/計算費工又費時)。所以PM的第一步不要急著去想「我要有哪些數據?」、「我想要怎麼呈現數據?」,這樣反而會掉進每個數據都想要的陷阱,應該要反過來思考:
- 你最終目的是要做什麼決策?(WHY)
- 為了達成目的,你過去會做哪些事?(HOW)
- 所做的每一件事背後,你會想採集哪些數據?(WHAT)
至於之後要怎麼撈資料、是做成資料庫還是儀表板、是要自己用還是提供給用戶,這些都是後面才要煩惱的事啦,千萬不要本末倒置了。
接著就跟大家分享傑瑞引導雙方討論的步驟,以及這些步驟是如何不著痕跡地偷渡Scrum的元素XD(最後面有總整理)~
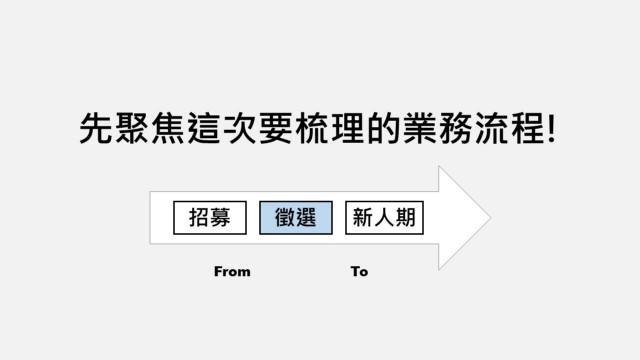
#Step 1:先釐清討論範圍
我會先請團隊定義這次討論的範圍是從哪裡到哪裡,這樣有三點好處:
- 讓大家更專注在目前要解決的流程上
- 後面討論如果不小心發散時,方便拉大家回來
- 讓大家頭腦開始暖身,開始思考範圍內過去遇到的問題
#Step 2:思考數據驅動是為了做什麼(WHY)
接著讓大家開始寫便利貼:如果有了數據,自己會想做什麼事情?一件事情寫一張便利貼。以這次的討論範圍「徵選流程」為例,包含:
- 我希望能知道整個徵選流程的進度或哪裡出現卡關?這樣主管問我時就能立刻回報
- 我希望能比較歷年徵選流程的狀況,這樣我們才能知道今年的成效
- 我希望能判斷不同履歷的好壞,這樣我們篩選進面試才會更有效率
- 我希望能知道什麼履歷適合哪個部門?這樣我們就能提升面試的通過率
有沒有發現這個步驟其實就是在請大家練習寫用戶故事(User story):
As a 招募人員
I want 知道整體徵選進度
So that 在主管問我時能立刻回報
只不過這邊的用戶故事顆粒度較大而已(屬於Epic),但是沒關係,後面我們會再繼續切割顆粒度,目的是先拿到團隊的數據需求。

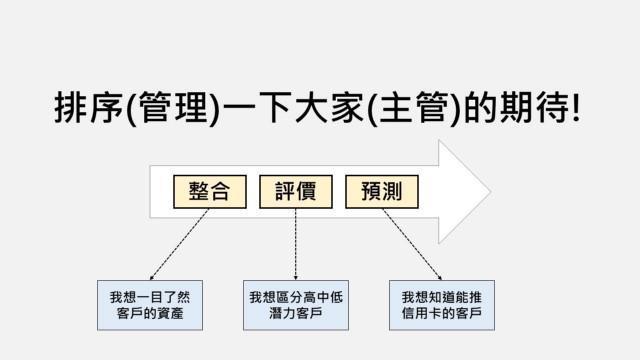
#Step 3:整理分類一下團隊的願望清單
團隊的需求總是很多,但資料分析師的產能卻是固定的。所以下一步要將需求稍作分類,分類的標準可以根據專案屬性來設計,因為這次是數據分析專案,所以傑瑞就按照數據分析的技術難度來分類(但畢竟我不是相關背景出身的啦,是從自身過去經驗來推敲,真正的資料分析師麻煩鞭小力一點XD)
- 整合類需求:單純地把既有數字整合起來(數量/比率),不需要用到太複雜的業務邏輯,如果以理財專員來舉例,需求大概就是「一目了然客戶的資產狀況」。
- 評價類需求:整合數字的過程要搭配大量且複雜的業務邏輯,例如PM要先幫忙定義怎樣的履歷才叫做好(以資料分析的語言稱作「加值規則」),PM要幫忙拆解履歷要看哪些指標以及好壞分數的門檻,回到理專的例子,需求大概會是「想區分高中低財富潛力的客戶」,一般企業常見的客戶分群或屬性貼標都是這類型需求。
- 預測類需求:例如前面提到的徵選需求「什麼履歷適合哪個部門」,除了要應用複雜的業務邏輯之外,可能還必須搭配資料建模、機器學習等分析技術(傑瑞一輩子都學不會!)。如果以數學來比喻,評價類需求大概是加減乘除,預測類需求就是迴歸分析(我承認都還給統計老師了!),而這類型需求也是資料分析師的價值所在。
而在這個步驟,傑瑞目的是請大家整理產品代辦清單(product backlog),將上一個步驟所寫的用戶故事(User story)用T-shirt size的概念來排序:
整合類需求 (技術難度 S)
評價類需求 (技術難度 M)
預測類需求 (技術難度 L)
等分類好之後,傑瑞也會提醒團隊要記得去管理主管的期待,告訴主管開發是有順序的,不要一開始就把期待拉到最高啊~(預測類需求)
#Step 4:持續切割需求顆粒度直到日常任務層
這邊運用的討論架構是參考顧客旅程地圖(user journey map),相信這個工具大家應該都不陌生了,目的是用來協助團隊拆解徵選流程的步驟(step)以及每個步驟底下不同的子任務(task),舉例以「判斷履歷的好壞」這個需求來說,步驟可能解拆解為1.收集履歷、2.計算分數、3.給予評價,而在2.計算分數這個步驟底下,子任務可能包含1.計算面試者英文測驗分數、2.計算面試者學經歷分數、3.計算主管面試分數、4.計算HR面試分數……等等。
最終目的是要讓大家拆解需求到日常工作層級,這樣才有辦法找出不同任務所對應的數據。
而這個步驟也是Scrum團隊平常用來梳理需求的方式之一,稱做refinement或grooming,需求顆粒度的大小最好切到能排進下次的衝刺週期(sprint),這樣開發團隊成員才有辦法拆解工作項目。

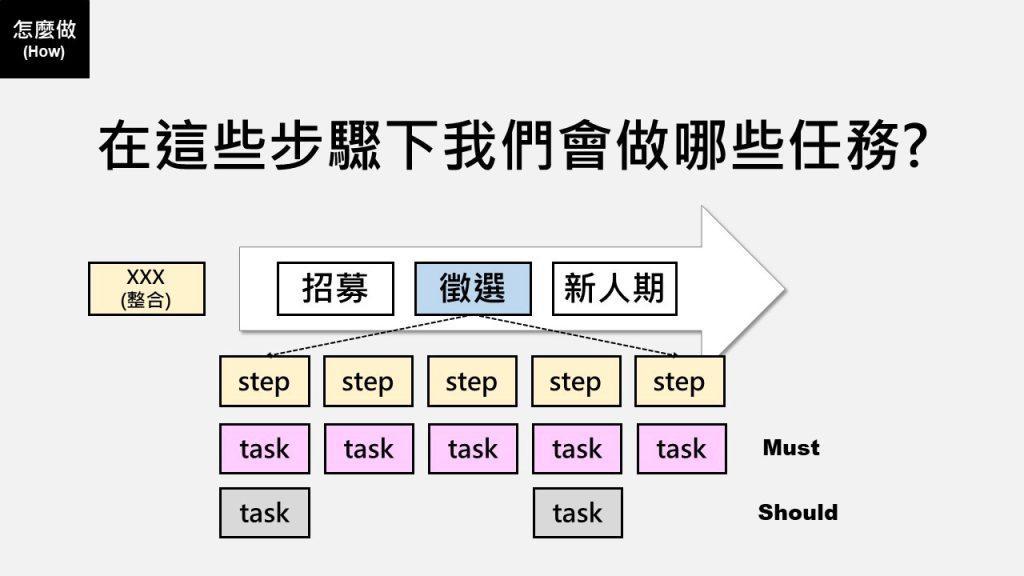
#Step 5:評估每個數據的效益與可行性
因為需求已經拆解到日常任務層級,因此PM應該就能輕而易舉寫下每個任務底下未來期望所產生的數據,剩下的就是讓PM與資料分析師來回溝通討論每個數據採集的效益與可行性,以方便雙方就數據開發面取得共識。
而最後這個步驟就是模仿Scrum團隊做衝刺任務規劃的雛形,也就是sprint planning。產品負責人(這邊是PM)與開發人員(這邊是資料分析師)共同一起釐清需求(這邊是期望產出的數據),針對需求的效益面以及可行性共同一起定義,最後再交由開發人員規畫後續開發工作。
傑瑞能夠協助雙方溝通的地方就到這了,剩下的就是讓團隊按照這個討論架構繼續去拆解不同的Epic需求或不同的業務流程囉,打完收工~
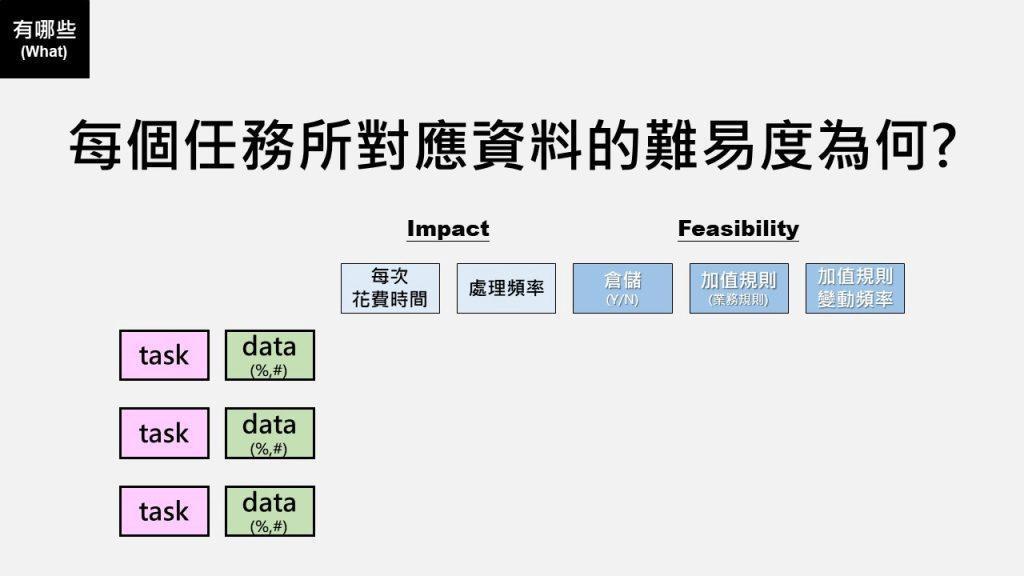
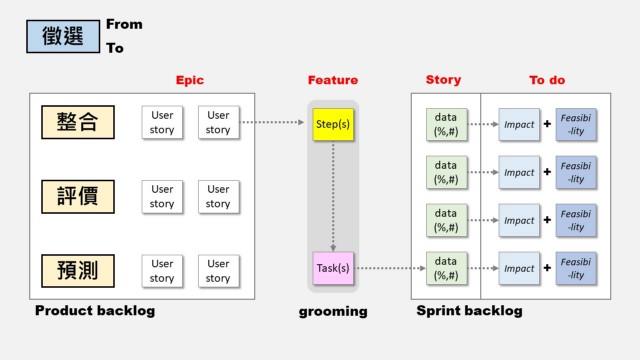
最後幫大家總結一下整個討論架構借鏡了哪些Scrum的元素,看完默默覺得自己是不是已經中Scrum的毒太深了XD~
瀏覽 1,034 次





