
Meta AI釋出蛋白質結構資料庫 含6.17億總體基因體學
為了不讓DeepMind專美於前,Meta AI近日釋出了多種用來預測蛋白質結構的模型,與含有6.17億種總體基因體學(Metagenomic)蛋白質結構的資料庫ESM Metagenomic Atlas,並表示這是全球最大的高解析度蛋白質預測資料庫,是既有任何蛋白質結構資料庫的3倍,也是第一個大規模覆蓋總體基因體學蛋白質的資料庫。
所謂基因編碼的蛋白質,不僅是複雜且動態的分子,也是生命的基礎,讓人類能夠看見,還可以對抗病毒,是驅動微生物與肌肉的馬達;而總體基因體學則是自然科學的新領域,利用基因定序來發現地球環境中的蛋白質,從土壤、深海或是體內的微生物,儘管現在人類對總體基因體知之甚少,但卻可能幫助人類解開進化的謎底,發現可能會有助於治癒疾病、淨化環境或是生產乾淨能源的蛋白質。
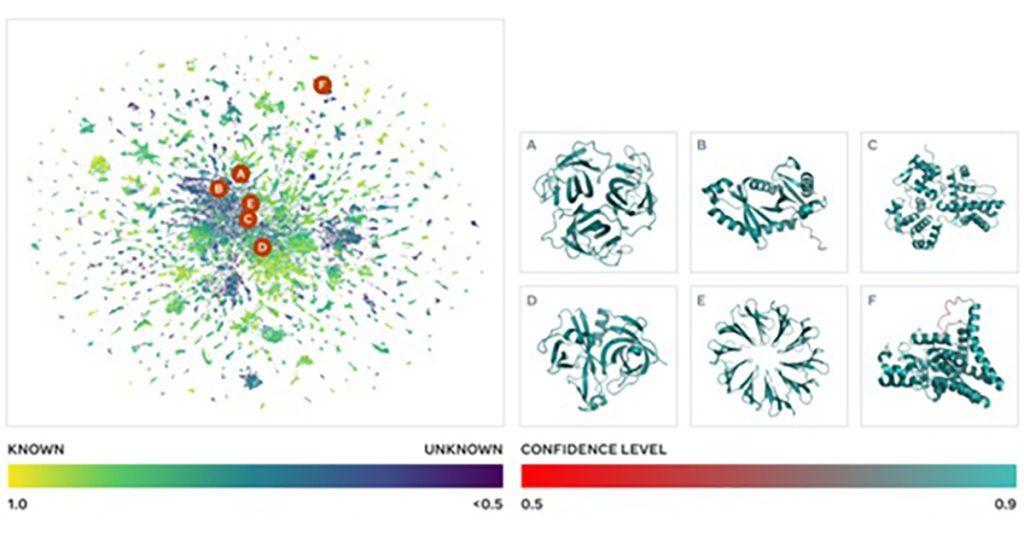
Meta AI的科學家因此打造了新的蛋白質結構預測方法ESMFold,利用大型語言模型ESM2的表徵,將蛋白質序列中生成準確的結構預測,速度可達到現有最先進蛋白質結構預測方法的60倍,但是ESMFold的準確度並不如DeepMind所開發AlphaFold。
外國《自然》期刊引用了Meta AI蛋白質研究負責人Alexander Rives的說法表示,他們團隊只用了兩的星期的時間,就利用ESMFold預測出超過6億種的蛋白質結構,而AlphaFold光是生產單一的蛋白質結構預測,可能就需要幾分鐘的時間。
目前Meta AI已釋出ESM Metagenomic Atlas的資料庫、所使用的各種模型與研究論文,以及可用來檢索特定蛋白質結構的API。(記者/竹二)
瀏覽 595 次




