
案例分析:製造業如何將AI和資料平台搬上雲|專家論點【黃婉中】
作者:黃婉中(雲端架構師)
最近幫一位製造企業將機器學習平台搬往雲端,在訪談過程中,客戶正面對以下挑戰:

經營面
目前製造業面對「少量多樣化」的巿場需求,有別於過往規模經濟下,產能高就是獲利保證的情況,現在需要針對特定客戶,製造特殊產品以符合需求。
為了保持競爭力,產線變得更忙了,卻因為良率和換線時間等因素,不見得能取得更高利潤。此外,客戶也積極尋找創造新服務的機會來增加營收,無論從生產經驗到資料,都期待能為企業創造多元收入。
技術面
儘管有了提高產能、創造新服務等明確目標,卻因為一些技術問題卡關。首先是企業內因為長年累積造成資料量龐大,並且種類繁多,需要取得這些資料就花上不少時間,而且不見得能取得足夠的資料。
其次是企業自行開發機器學習平台後,不僅維運不易,多系統間的資安卡控必須搭配內規,作嚴謹的設計。同時間,又要考量如何與內部資訊共享,以避免重複工作。
另外,多年前所規劃的電腦算力,早已不符所需,得出結果到調整產線,可能已經是數周後的事情。
雲端解決方案怎麼幫助客戶?
團隊花了三個月時間,進行整體架構規畫。將專案細分成不同的小專案,由不同架構師、合作夥伴及客戶端工程師協作完成。整個方案主要使用Azure平台上面的資料服務,包含 Data Lake、Synapse、Databricks與機器學習。
首先,將數十TB的telemetry data,從地端資料倉儲中搬上雲,並把散落於不同來源的資料,如 Oracle和SQL的資料也搬上來。
同時,架構師也跟資料科學家緊密合作,將資料使用於Databricks及Azure Machine Learning中。針對可直接呈現、不需要再運算的資料,利用Power BI呈現。
更進一步的說明如下圖架構所示,使用C# 整合 Azure Storage,將檔案依 size 分割,同步平行上傳。接著,使用 Polybase 建立外部資料表為了後續資料載入做準備。
根據需求,使用 Databricks 來清理和轉換資料,並儲存在 ADLS Gen2,之後就可以利用 Databricks 和 Synapse 之間的原生連接器,大規模存取和移動資料集。
最後,將測試過的模型用Azure Machine Learning Service和Container Registry進行容器化和部屬。另外,也可利用Azure Analysis Service和Power BI做視覺化呈現。
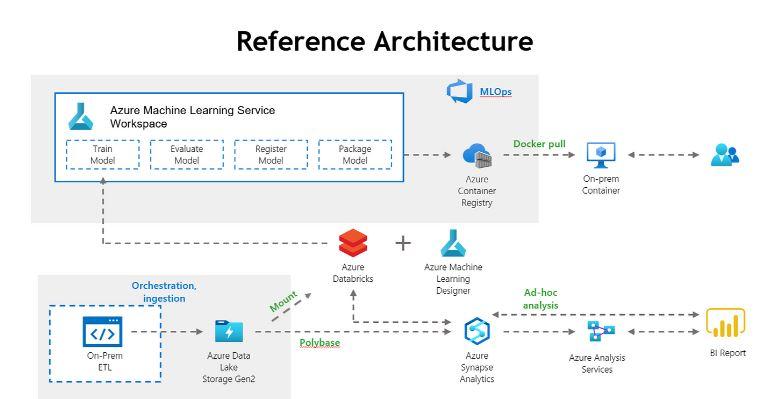
以上是上雲專案的動機和架構。下一篇,我將分享成果以及過程中的挑戰。
瀏覽 863 次





